The Simulation Hypothesis for Other Language Model Architectures
No, not that one.
In 2022, Janus suggested that the best way to think about LLMs is not as oracles, agents, tools, or behaviour cloners, but as simulators. I think his conceptual analysis is very useful and persuasive.
I also think it needs to be rethought in light of new architectures, training paradigms, and applications. Here, I want to take a closer look at diffusion LLMs (dLLMs) and chain-of-thought (CoT) models. I think understanding LLMs as simulators holds up, but needs to be applied carefully.
Simulation Hypothesis Redux
A very quick summary of the Simulation Hypothesis. Skip if you already know this, all errors are mine, not Janus’.
The AI which the alignment community was most afraid of was the hypercapable goal-achiever. The model that disables its own off-switch when you ask it to fetch you a coffee, or turns the universe into paperclips. We call that instrumental convergence1.
The AI which we got is … weird. It can be the helpful assistant in one moment, then threaten you and become a supervillain in the next. It can be frustratingly dim, until it suddenly gains IQ points when asked to think step by step or offered a bribe.

The Simulation Hypothesis offers a way to think about the scary goal-optimizer AI and how it relates to the weird language models we got. What Janus calls an “ontology”.
He distinguishes the model, which is optimized to be really good at next-token-prediction, from the persona that the user is interacting with. The persona sommetimes exhibits agentic behaviour, but the model itself is not a goal-optimizer. The model architecture is somewhat well understood2, but the behaviour of the persona is much more interesting to users and researchers. That’s because it’s what we directly interact with, and it’s the thing that exhibits behaviour.
Janus suggests calling the model itself the Simulator, and the persona the Simulacrum. The Simulator is like physics: Based on an initial condition, it predicts the next state. The Simulacrum is an emergent phenomenon, which manifests from the aggregate of many next step predictions. Think of it as a trace or path integral, if you like. Simulacra is what we want to study.
Comparing the simulator to physics gives useful intuitions:
- We can expect understanding simulacra based on just a snapshot of model activations to be hard, the same way we would find it difficult to understand a complicated mechanism based on just the masses and velocities of a set of particles.
- Initial conditions will have a really big influence on the Simulacrum we get and we shouldn’t expect maximal capability from every trace.
- Changing how the Simulator is trained will only impact the Simulacra as a second-order effect. In other words, you can only tweak the laws of physics of your simulation, but you cannot directly impact the Simulacrum at training time.
Chain-of-Thought Reasoners: Changing the physics
How would we use Janus’ ontology to think about chain-of-thought models?
My understanding of how frontier models get high performance out of CoT reasoners is far from complete. We don’t have all the information, but we can speculate that two components are involved:
- Supervised fine-tuning on good human data
- Giving the model a scratchpad that’s not used in evaluation
In the language of the Simulation Hypothesis, supervised fine-tuning translates to “bending the laws of the Simulator’s physics into a shape in which the sort of interactions we see provide in the training set become more likely”.
The scratchpad can be described as a mix of two things. First, the setting up of specific initial conditions for the model via a system prompt instructing the model to use a scratchpad. Second, the fine-tuning of the model to actually make use of the scratchpad, which, again, bends physics to make scratchpad use more likely.
The intuition of bending physics generates at least one interesting question in an alignment context. We can think of the space of all possible texts generated by a model as a state space, and ask what the attractor states in that space are. For a raw model which hasn’t been fine tuned, there are many different grooves for the Simulacrum to fall into: helpful assistant, SEO trash, bond villain, etc.
For a model after fine-tuning, we hope that some attractor states have been eliminated completely. A question to ask: Can we prove this? Can we search for a path from a safe state to a dangerous one?
Diffusion LLMs: What is the direction of time?
Finally, I want to make a note about diffusion LLMs. These are not next-token predictiors. Instead they work by “denoising” the output token stream. Noise is introduced by randomly occluding some tokens – for a much better explanation see this paper, from which I’ve clipped the figure below.
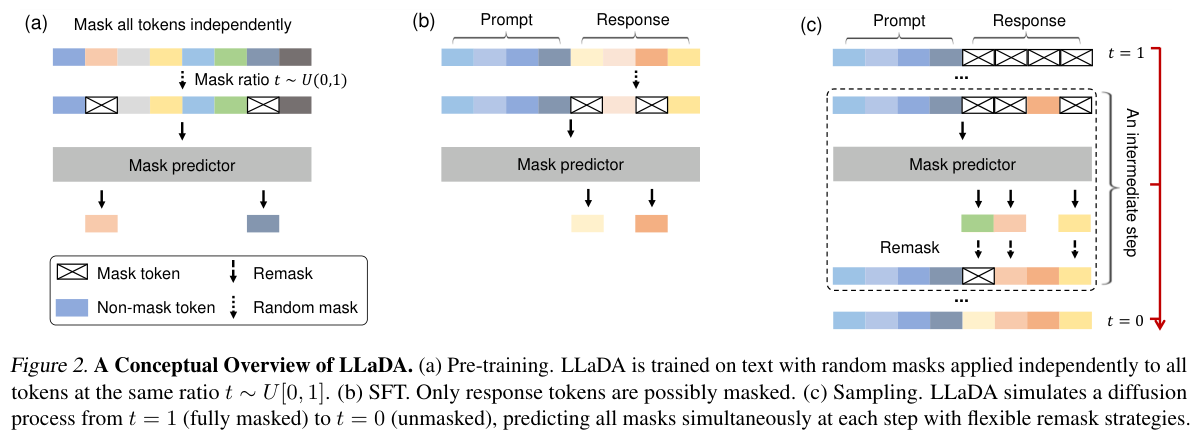
Is the Simulator / Simulacrum ontology still applicable here? I think the answer is yes, if we separate the direction of generation time from the token index. For transformers, which sample token-by-token, the axis of time is aligned with the token index, meaning that the n-th output token is generated at the n-th inference iteration of the trained model.
For diffusion model, this is not the case. At time step t, it might generate a whole bunch of output tokens, spread across the output window.
We still retain the metaphor of “physics”, but the direction of simulation is through diffusion space, not LTR on the token output stream.
To quote the Daily Mail: “We don’t know what it means but we are scared”.3
-
Almost everyone who reads this already nows this, but instrumental convergence is just really fun to say in my head. It’s almost like it’s reverbarating, but the echo is not my voice but instead deeper, and layered, spoken in what sounds like a primordial demonic language… I’m sure it’s not just me. ↩
-
I think a lot of the magic happens in commercial data generation, which, for the most part, isn’t publically discussed. ↩
-
Daily Mail, Front page, 18 February 2023. ↩